产生背景
MapReduce这种并行编程模式思想最早是在1995年提出的,首次提出了“map”和
“fold”的概念,和Google现在所使用的“Map”和“Reduce”思想相吻合。
“fold”的概念,和Google现在所使用的“Map”和“Reduce”思想相吻合。
与传统的分布式程序设计相比,MapReduce封装了并行处理、容错处理、本地化计算、负载均衡等细节,还提供了一个简单而强大的接口。通过这个接口,可以把大尺度的计算自动地并发和分布执行,使编程变得非常容易。另外,MapReduce也具有较好的通用性,大量不同的问题都可以简单地通过MapReduce来解决。
MapReduce把对数据集的大规模操作,分发给一个主节点管理下的各分节点共同完成,通过这种方式实现任务的可靠执行与容错机制。在每个时间周期,主节点都会对分节点的工作状态进行标记,一旦分节点状态标记为死亡状态,则这个节点的所有任务都将分 配给其他分节点重新执行。
据相关统计,每使用一次Google搜索引擎,Google的后台服务器就要进行1011次运算。这么庞大的运算量,如果没有好的负载均衡机制,有些服务器租用的利用率会很低,有些则会梦荷太重,有些甚至可能死机,这些都会影响系统对用户的服务质量。而使用MapReduce这种编程i式,就保持了服务器之间的均衡,提高了整体效率。
编程模型
MapReduce的运行模型如图2-2所示。图中有M个Map操作和R个Reduce操作。
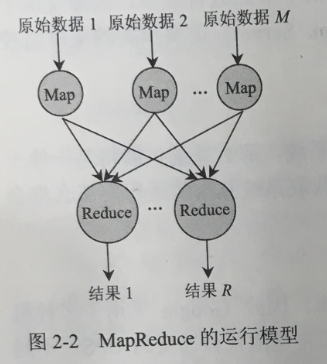
简单地说,—个M函数就是对一部分原始数据进行指定的操作。每个Map操作都针对不同的原始数据, 因此Map与Map之间是互相独立的,这使得它们可以充分并行化。一个Reduce操作就是对每个Map所产生的一部分中间结果进行合并操作,每个Reduce所处理的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的结果集,因此Reduce也可以在并行环境下执行。
在编程的时候,开发者需要编写两个主要函数:
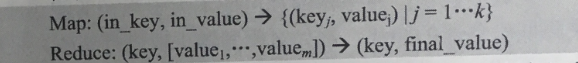
Map和Reduce的输入参数和输出结果根据应用的不同而有所不同。Map的输入参数是in_key和in_value,它指明了Map需要处理的原始数据是哪些。Map的输出结果是一组<可以,value>对,这是经过Map操作后所产生的中间结果。在进行Reduce操作之前,系统已经将所有Map产生的中间结果进行了归类处理,使得相同key对应的一系列value能够集结在一起提供给一个Reduce进行归并处理,也就是说,Reduce的输入参数是(key, [value1,…,valuem])。Reduce的工作是需要对这些对应相同key的value值进行归并处理,最终形成(key,final_value)的结果。这样,一个Reduce处理了一个key,所有Reduce的结果并在一起就是结果。
例如,假设我们想用MapReduce来计算一个大型文本文件中各个单词出现的次数, Map的输入参数指明了需要处理哪部分数据,以“<在文本中的起始位置,需要处理的数据长度>”表示,经过Map处理,形成一批中间结果“<单词,出现次数>。而Reduce函数处理中间结果,将相同单词出现的次数进行累加,得到每个单词总的出现次数。
