一致性问题是Chubby需要解决的一个关键性问题,那么Paxos算法在Chubby中究 竟是怎样起作用的呢?
为了了解Paxos算法作用,需要将单个副本的结构剖析来看,单个Chubby副本结构 如图2-8所示。图2-8单个Chubby副本结构从图中可以看出,单个副本主要由以下三个层次组成。
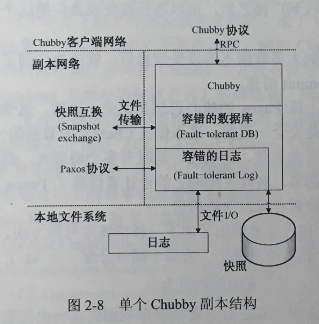
(1)最底层是一个容错的日志,该日志对于数据库的正确性提供了重要支持。不同副本上日志的一致性正是通过Paxos算法来保证的。副本之间通过特定的Paxos协议进行 通信,同时本地文件中还保存有一份同Chubby中相同的日志数据,
(2)最底层之上是一个容错的数据库,这个数据库主要包括一个快照(Snapshot)和 一个记录数据库操作的重播日志(Replay-log),每一次的数据库操作最终都将提交至曰志中。和容错的日志类似的是,本地文件中也保存着一份数据库数据副本。〃
(3)Chubby构建在这个容错的数据库之上,Chubby利用这个数据库存储所有的数据。Chubby的客户端通过特定的Chubby协议和单个的Chubby副本进行通信。
由于副本之间的一致性问题,客户端每次向容错的曰志中提交新的值(value)时, Chubby就会自动调用Paxos构架保证不同副本之间数据的一致性。图2-9显示了这个过程。
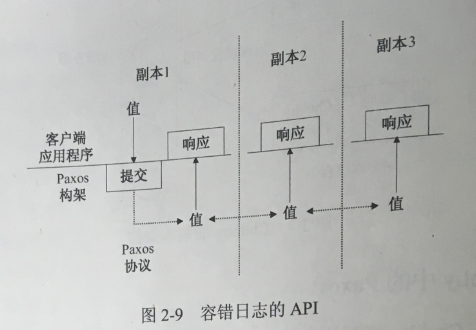
结合图2_9来看,在Chubby中Paxos算法的实际作用为如下三个过程。
(1)选择一个副本成为协调者(Coordinator)。
(2)协调者从客户提交的值中选择一个,然后通过一种被称为accq)t的消息广播给所有的副本,其他的副本收到广播之后,可以选择接受或者拒绝这个值,并将决定结果反馈给协调者。 .
(3)—旦协调者收到大多数副本的接受信息后,就认为达到了一致性,接着协调者向相关的副本发送一个commit消息。
上述三个过程实际上跟Paxos的核心思想是完全一致的,这些过程保证提交到不同副本上容错日志中的数据是完全一致的,进而保证Chubby中数据的一致性。
由于单个的协调者可能失效,系统允许同时有多个协调者,但多个协调者可能会导致多个协调者提交了不同的值。对此Chubby的设计者借鉴了Paxos中的两种解决机制:给 协调者指派序号或限制协调者可以选择的值。
针对前者,Chubby的设计者给出了如下一种指派序号的方法。
(1)在一个有n个副本的系统中,为每个副本分配一个idi(r) 其中0≤i(r)≤n-1.则副本的序号s= k×n+i(r),其中k的初始值为0。
(2)某个副本想成为协调者之后,它就根据规则生成一个比它以前的序号更大的序号(实际上就是提高k的值),并将这个序号通过propose消息广播给其他所有的副本。
(3)如果接受到广播的副本发现该序号比它以前见过的序号都大,则向发出广播的副本返回一个promise消息,并且承诺不再接受旧的协调者发送的消息。如果大多数副本都返回了 promise消息,则新的协调者就产生了。
对于后一种解决方法,Paxos强制新的协调者必须选择和前任相同的值。
为了提高系统的效率,Chubby做了一个重要的优化,那就是在选择某一个副本作为协调者之后就长期不变,此时协调者就被称为主服务器(Master)。产生一个主服务器避免了同时有多个协调者而带来的一些问题。
在Chubby中,客户端的数据请求都是由主服务器来完成,Chubby保证在一定的时间内有且仅有一个主服务器,这个时间就称为主服务器租用期(Master Lease)。如果某个服务器被连续推举为主服务器的话,这个租约期就会不断地被更新。租续期内所有的客户请求都由主服务器处理。客户端如果需要确定主服务器的位置,可以向DNS发送一个主服务器定位请求,非主服务器的副本将对该请求做出回应,通过这种方式客户端能够快速、准确地对主服务器做出定位。
需要注意的是,Chubby对于Paxos论文中未提及的一些技术细节进行了补充,所以Chubby的实现是基于Paxos,但其技术手段更加的丰富,更具有实践性。但这也导致了最终实现的Chubby不是一个完全经过理论上验证的系统。
