SDB出现的一系列问题是由于它的“简单”特性造成的,SDB主要有以下两个方面的问题? 一方面是支持的操作类型不够,像连接、对结果的排序这样的重要操作目前SDB都不支持,这些工作用户必须自己通过程序来完成,当然也不排除Amazon会在日后向SDB中添加这样的功能。另一方面的问题是由它的简单存储方式造成的,所有的数据在SDB中都以字符串形式存储,因此在做查询操作时采取的是词典顺序(Lexicographical Order),有些时候直接釆用这种比较方法会出现一些意想不到的问题。对于这类问题,Amazon也提供了以下一些解决方式。
(1)整数补零(Zero Padding)。一般情况下对数字20和100的比较很简单,20显然排在100之前,但是用字符串方式存储并按词典顺序比较则结果相反,因为1排在2之前。对于这种情况。Amazon建议在整数之前补零。也就是用00020和00100进行比较,显然这可以得到和按数字顺序比较一样的结果。
(2)对负整数集添加正向偏移量(Negative Numbers Offsets)。这种方法就是对有负数在的数据集中的每个数加上一个较大的整数,使负数全部变成整数,相当于对所有数做正偏移,如此就能保证比较结果的准确性。
(3)采用ISO 8601格式对日期进行转换(Convert Dates to Strings Following ISO 8601 Format)。ISO 8601格式的具体要求大家可以查阅相关标准。
Simple DB和其他AWS的结合使用
SDB对于值的大小限制是由于Amazon希望用户能充分地综合应用AWS的各个服务器租用组件,实际上如果用户可以恰当地选择AWS组件并加以运用,将会收到很好的效果。
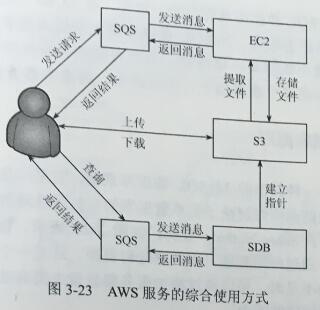
图3-23是典型的AWS服务综合使用方式。用户将需要处理和存储的数据上传至S3,需要时可以随时下载。当上传成功后可以通过SQS对SDB执行一系列操作,将S3中需要处理的文件位置(指针)存储在SDB中。利用这些指针,配合SQS,向EC2发出命令,让EC2的某个实例从S3中提取相关文件进行处理,成功处理后将文件再回存至S3并把处理结果返回给用户。当然用户也可以直接向EC2发出指令从S3中直接取文件,但这样的读取速度肯定没有利用文件指针的速度快,特别是在取大量的分散文件时这种速度差异会更明显。所以合理地搭配使用AWS的备个组件可以快速、有效地完成用户的任务。